- Product
- Solutions
Solutions
Unparalleled performance for organizations requiring maximum security, control and efficiencyTailored automated gating pipelines trained on your data, for your useStreamline your data journey with automated uploads, end-to-end traceability, and integrated analysis - Resources
- Support
- Pricing
- Sign In
Flow Cytometry Software, Reimagined
Streamline your flow cytometry analysis with innovative, cloud-based software
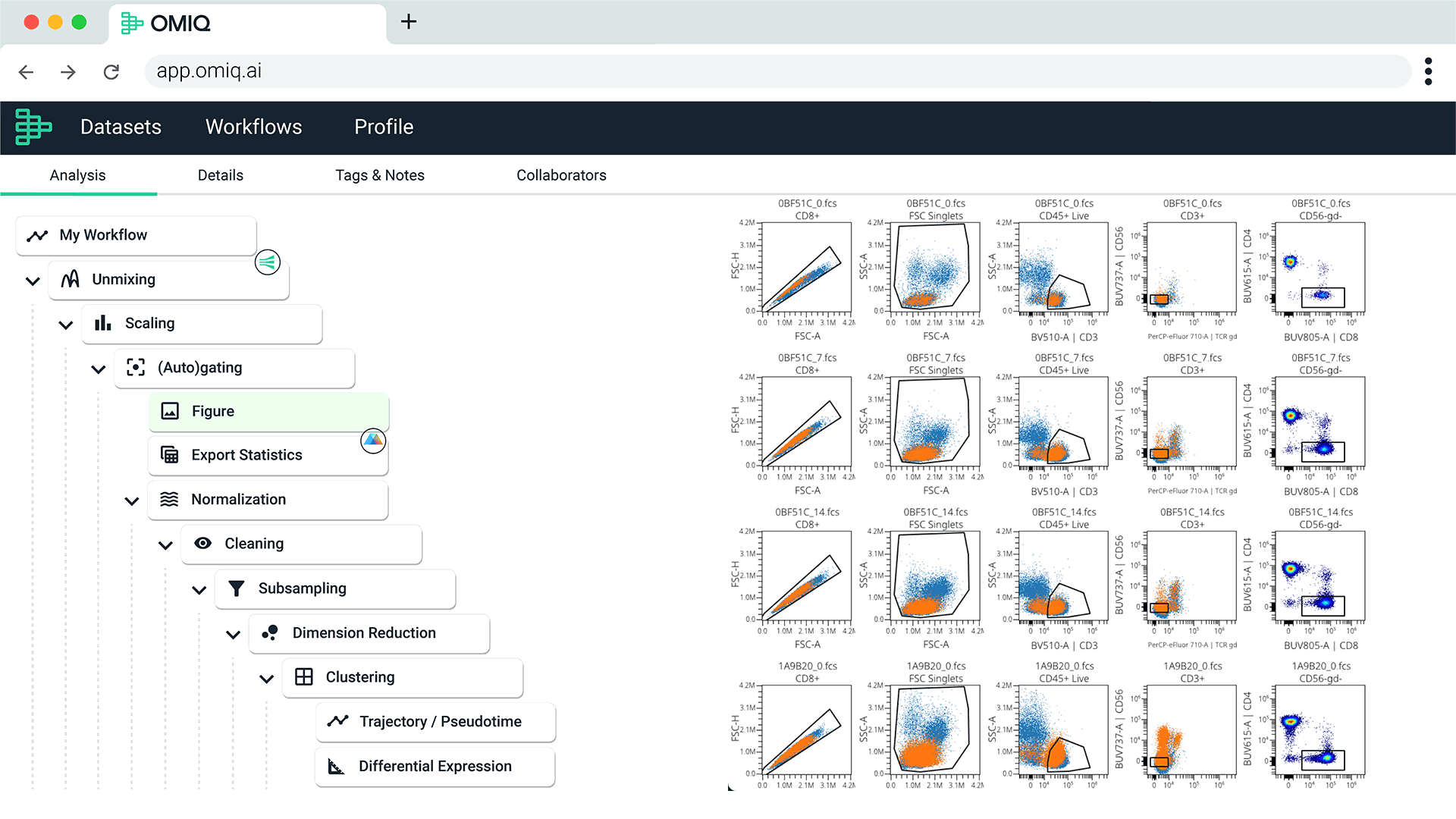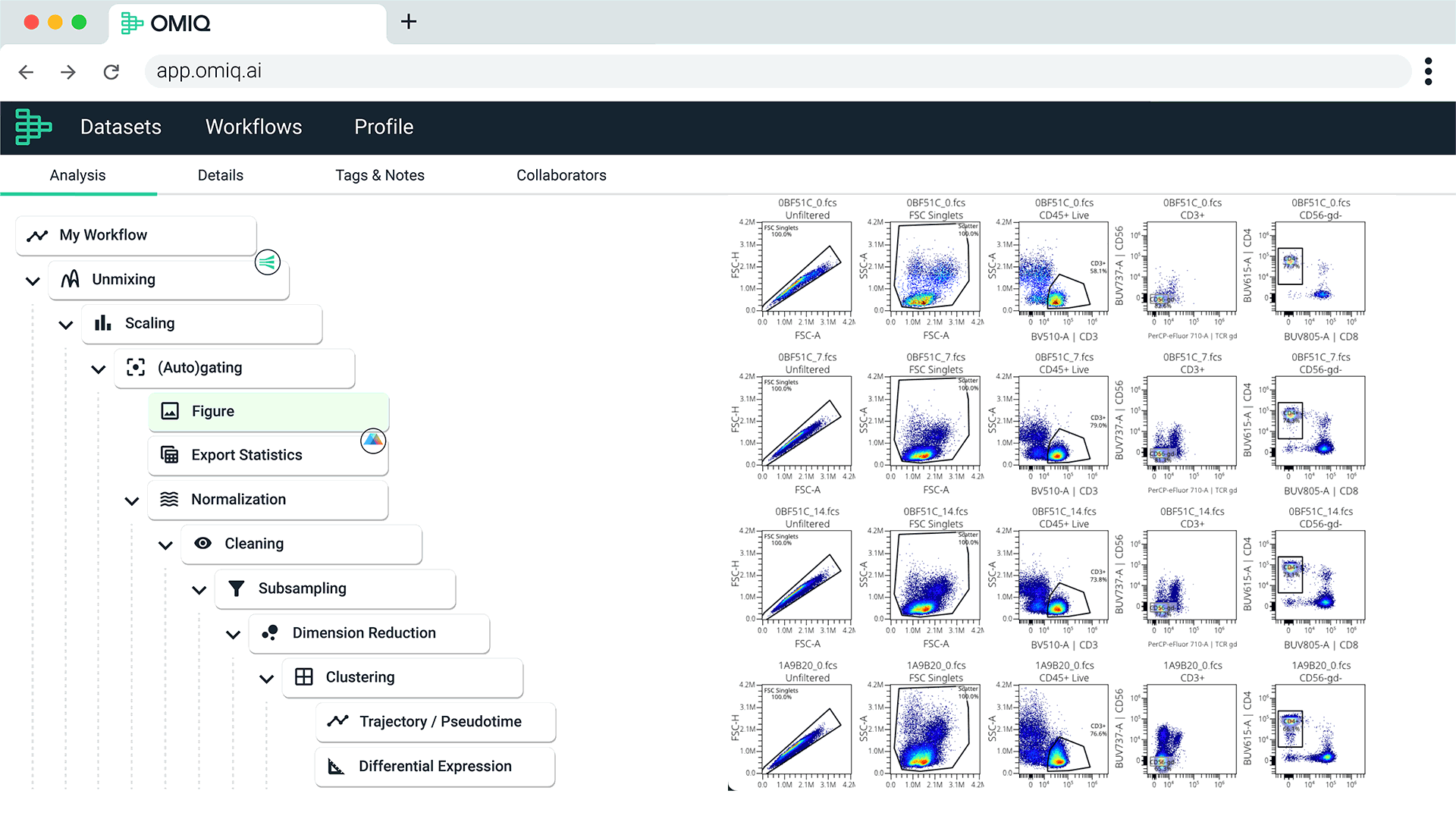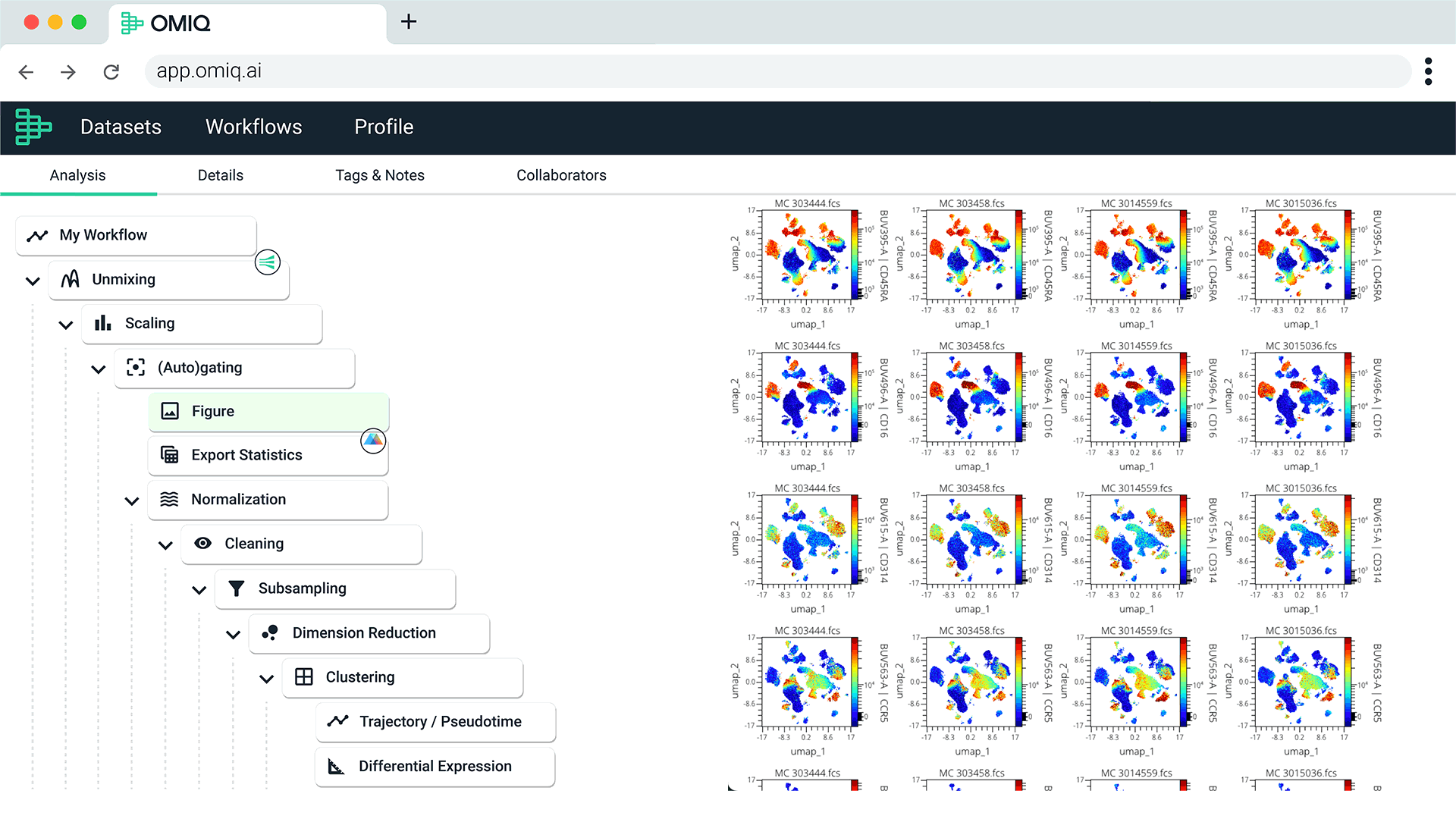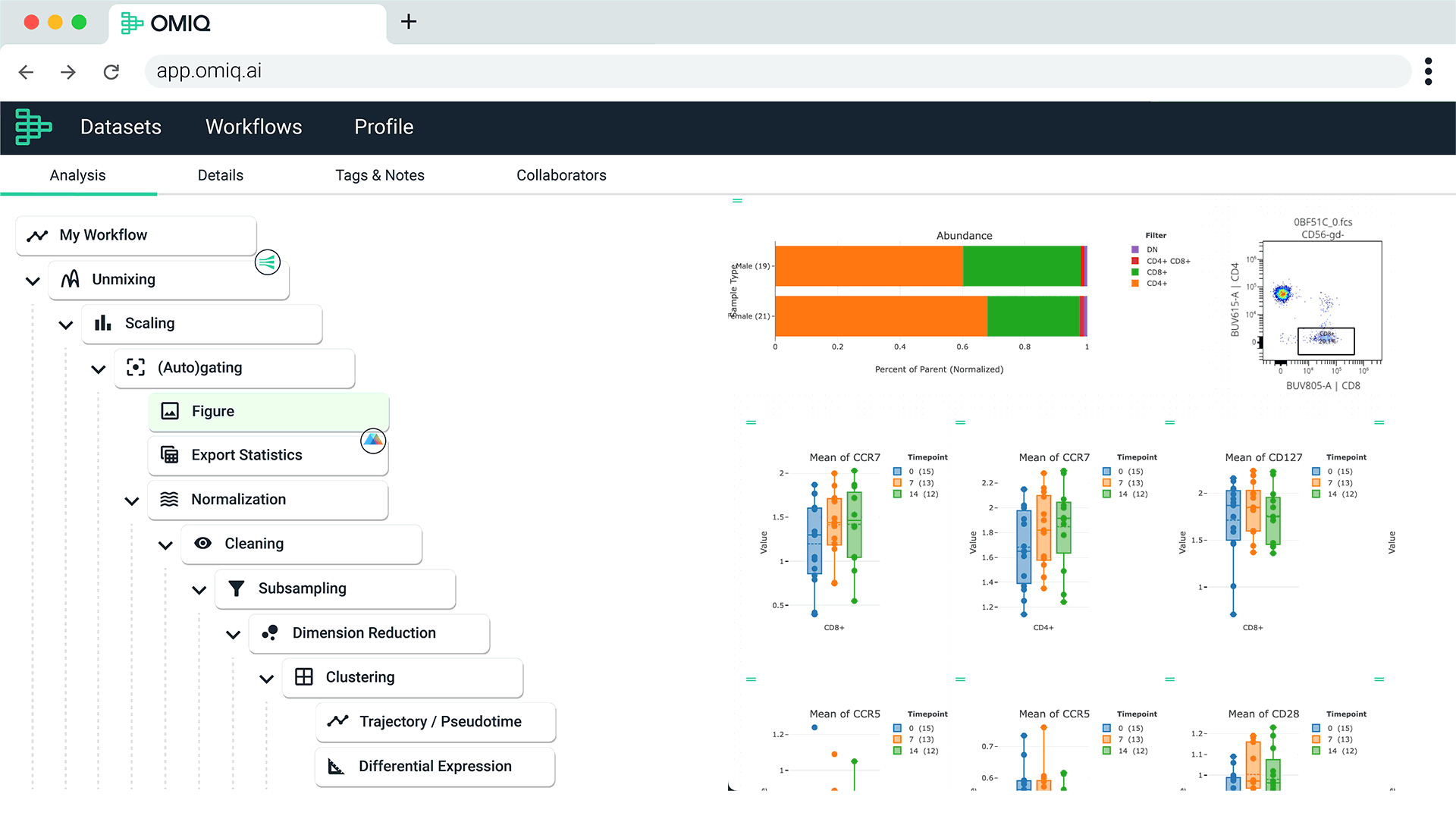
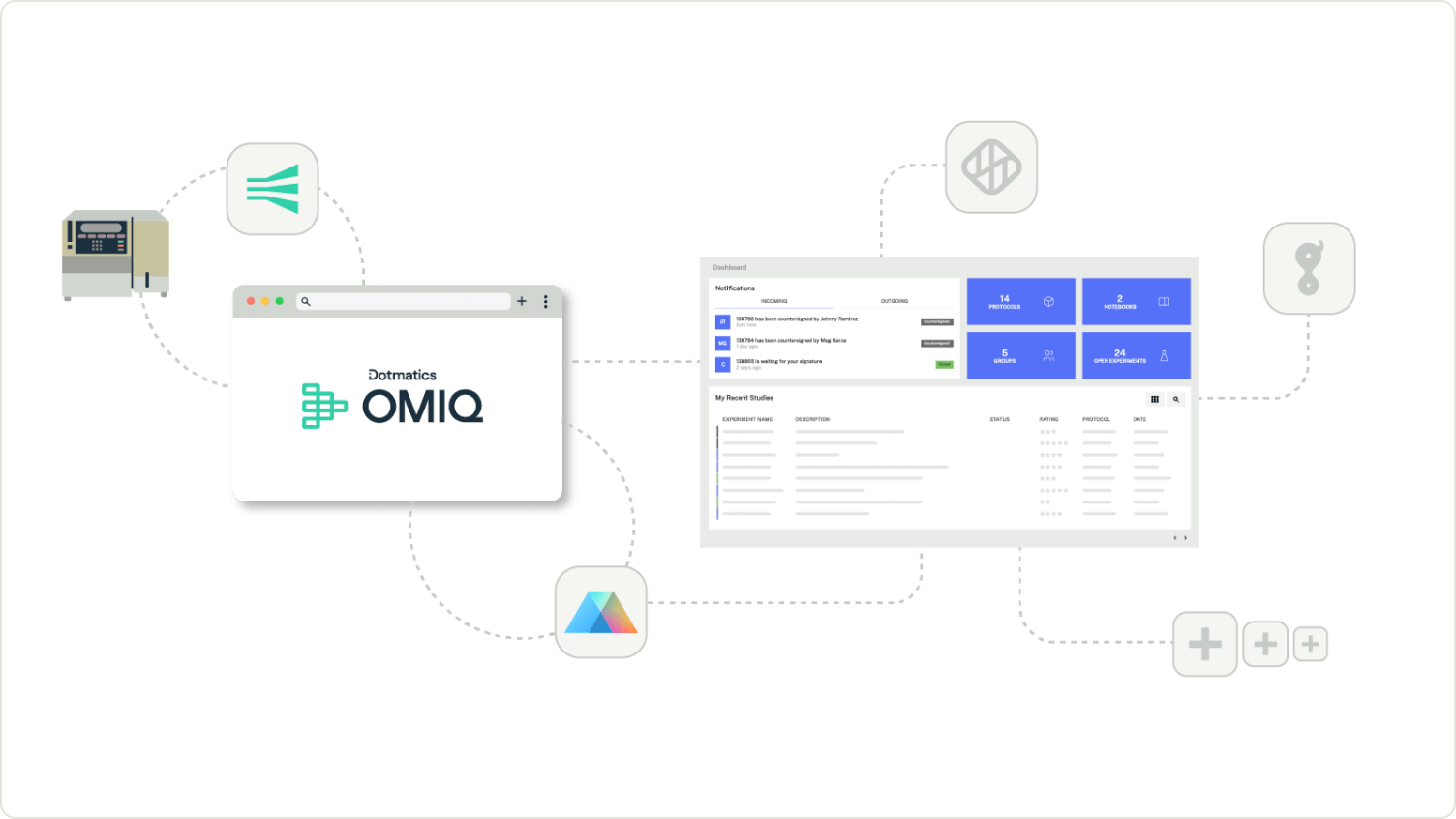
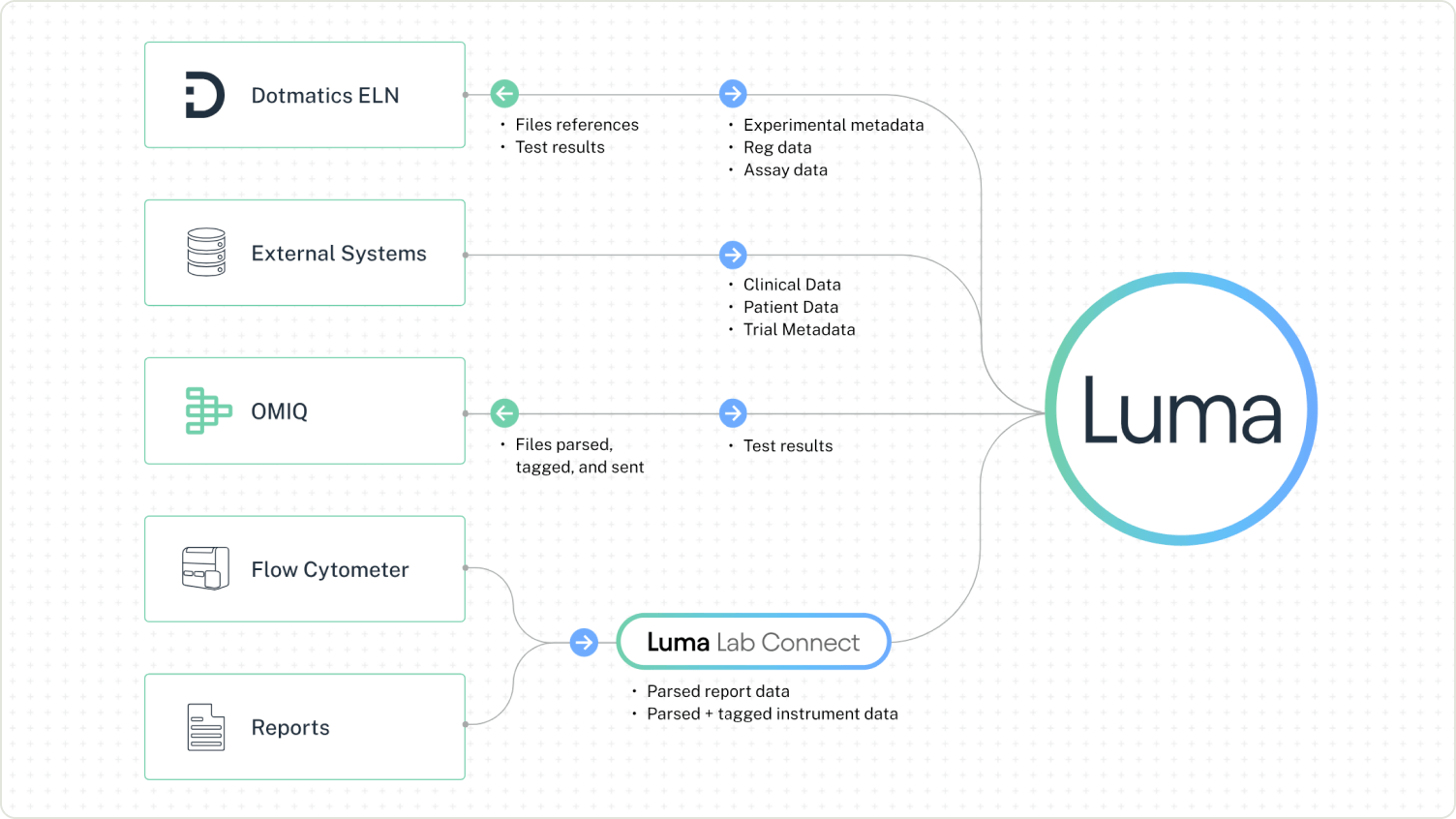
End-to-End Analysis with Seamless Integrations
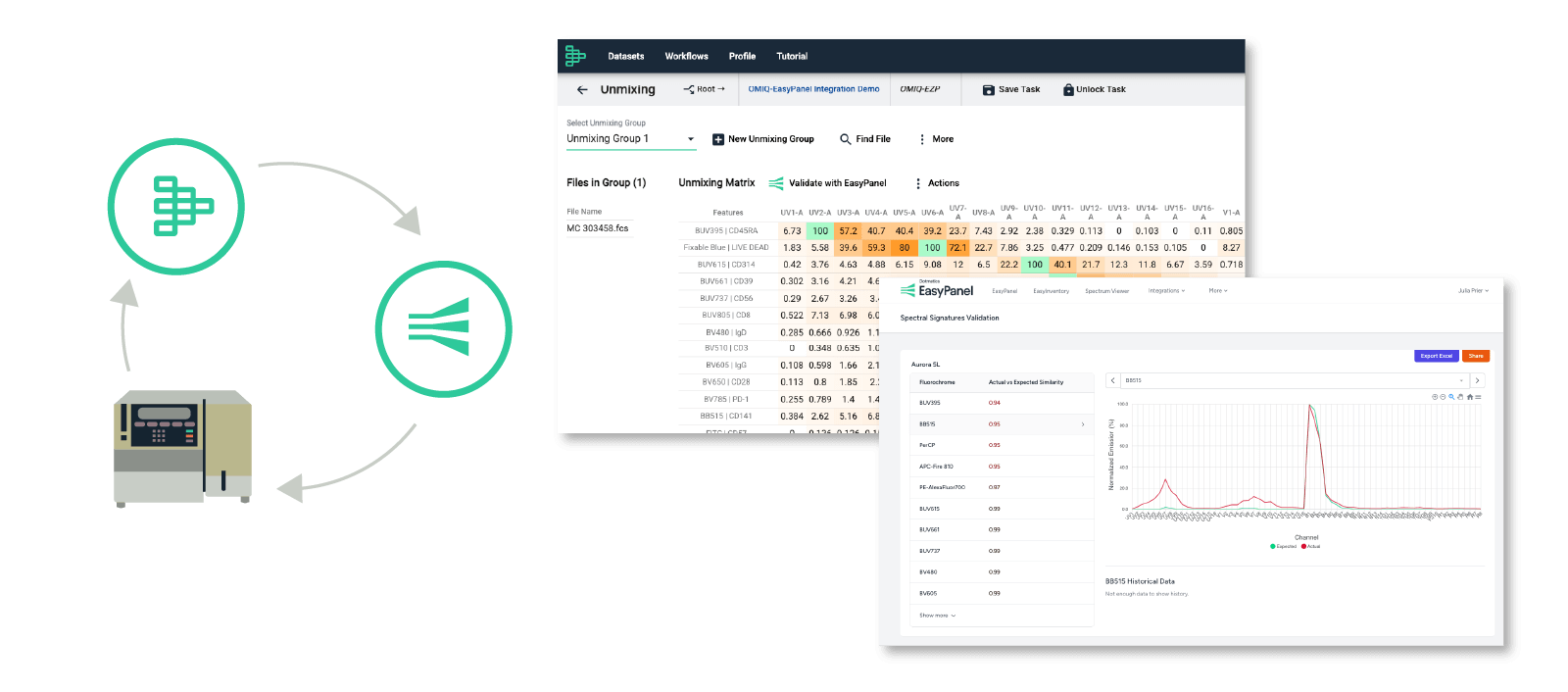
Directly import data from your flow cytometers to OMIQ. Learn more.
Automatically validate your spectral signatures. Learn more.
Effortlessly transfer your data to Prism with no manual reshaping. Learn more.
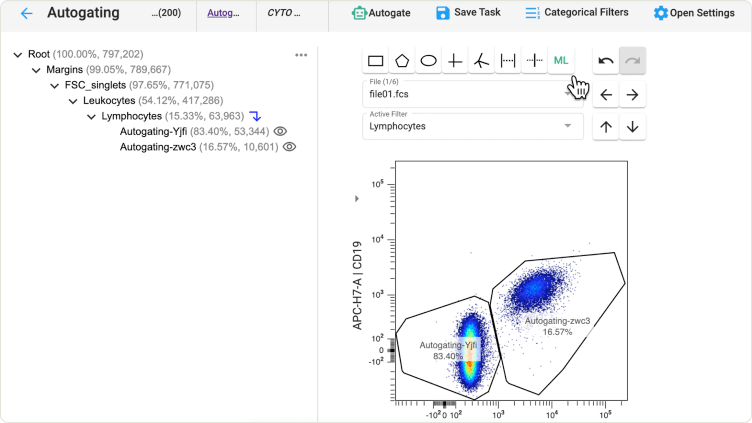
Modern Cloud Software for Classical and Advanced Flow Cytometry Analysis
Complete your entire workflow in one software, from raw data to statistical significance, using classic flow cytometry tools seamlessly blended with the latest algorithms and visualizations
Where Flow Cytometry Meets Data Science
OMIQ helps make sense of the chaos of cytometry analysis with workflows and metadata providing clear visual touchpoints and reducing manual data handling and its associated risks.
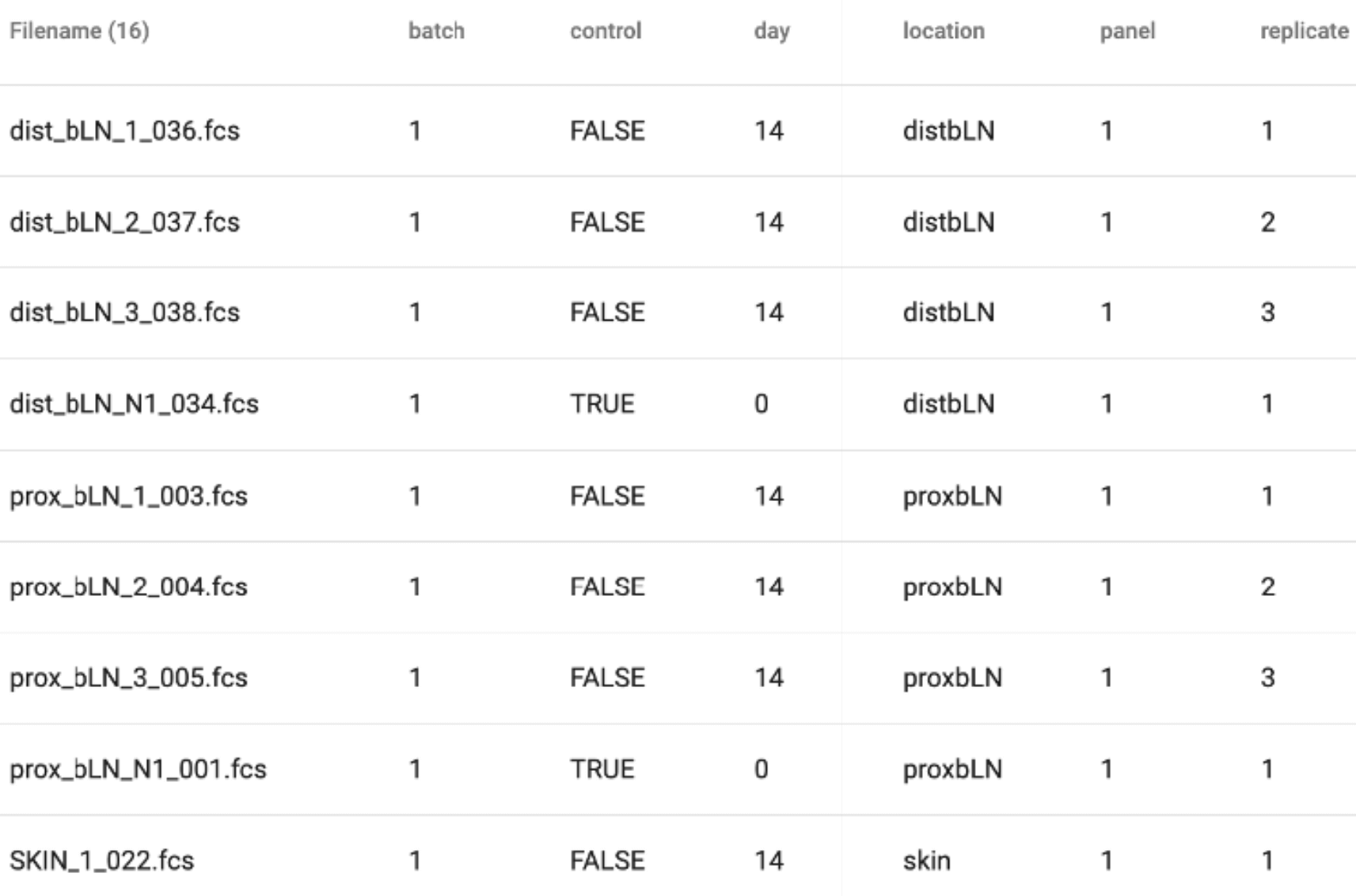
Metadata Annotation
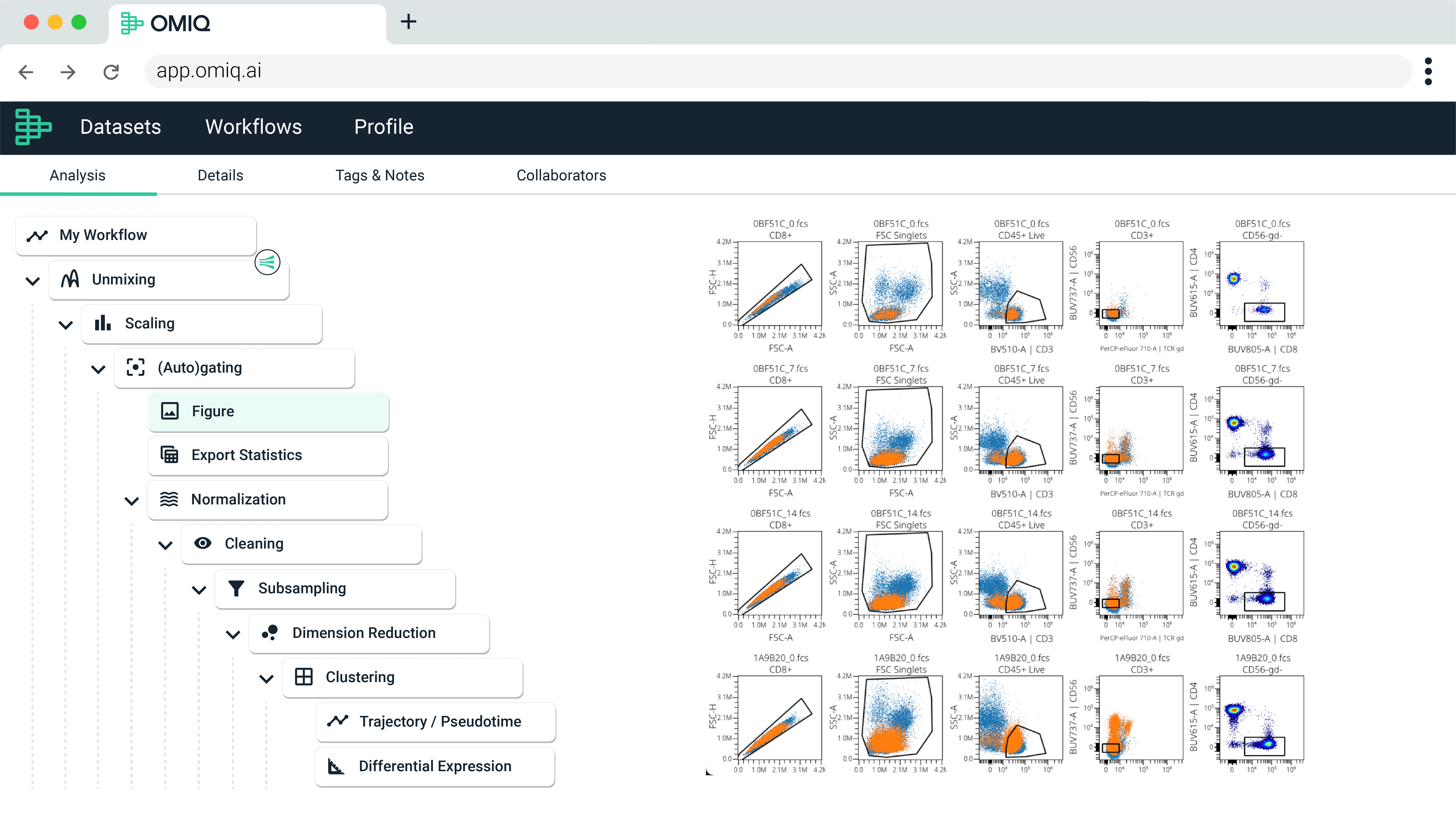
Concatenate, gate, group, filter, or sort by metadata to transform your raw flow cytometry data into valuable, interpretable information.
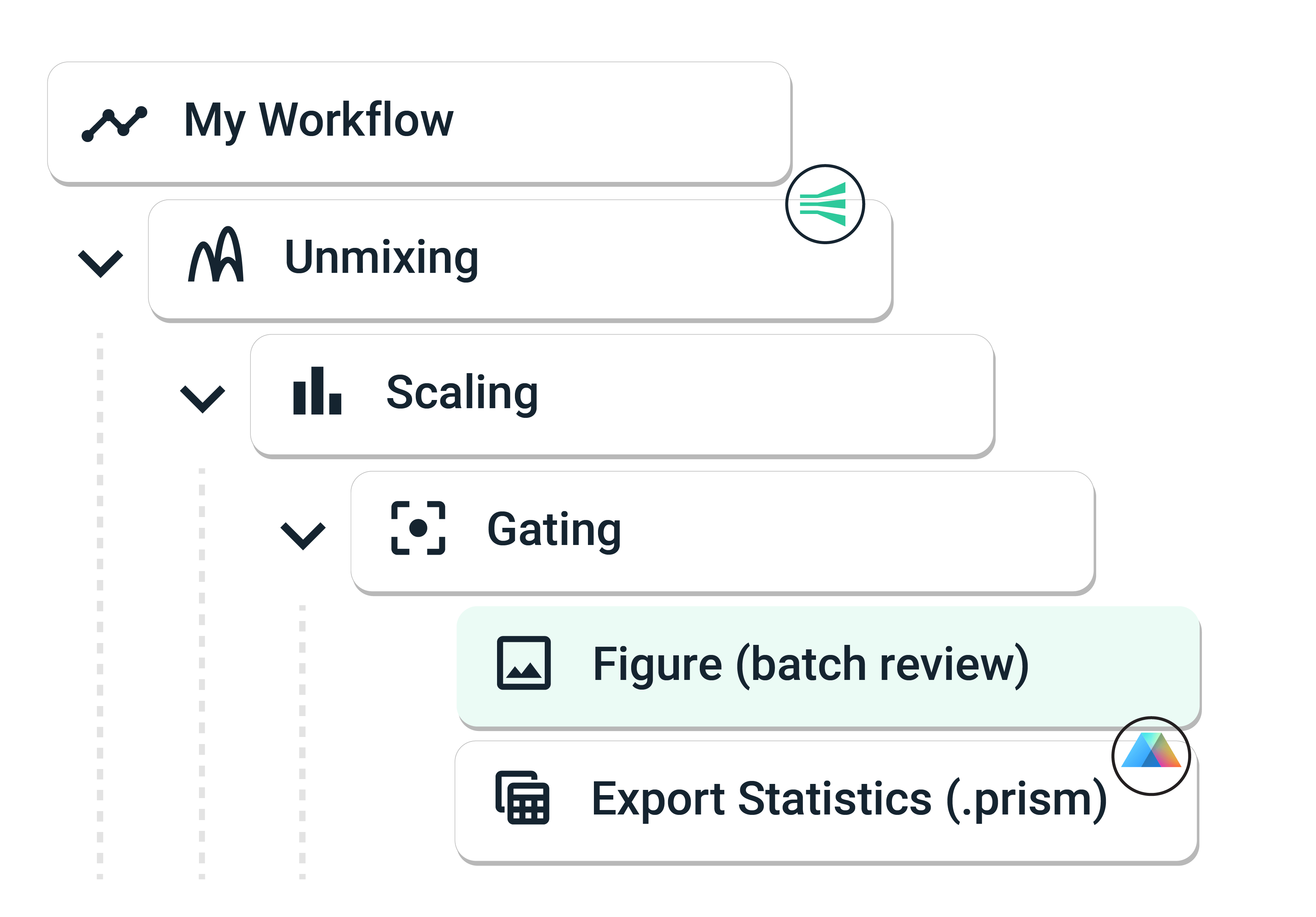
Intuitive Workflows
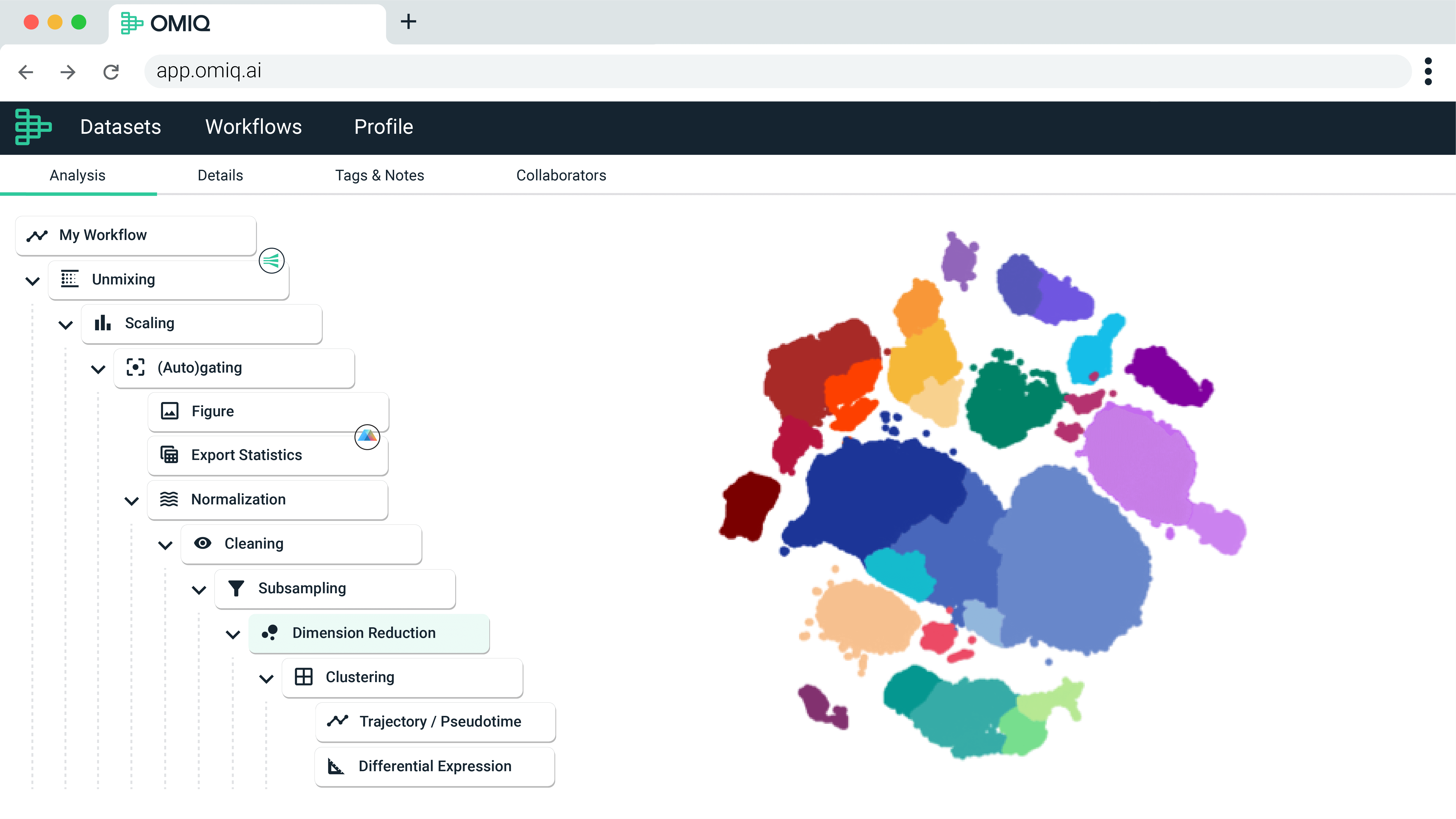
Workflows provide a step-by-step view of all analysis tasks. Create and configure workflow templates to automate your analysis and enable sharing, versioning, and reproducibility.
From Ideas to Insights, Faster
Remove the data bottleneck with custom solutions designed to scale your analysis pipelines
Trusted by the world’s leading research organizations




Experience the future of flow cytometry.